@TOC
一、通过Fiddler抓包获取到小程序的配置信息文件,其中包含ttpkg.js文件的路径
抓包相信大家肯定已经会了吧,不会的可以参考
吾爱和看雪论坛的相关文章
二、浏览器打开对应的ttpkg.js文件,并保存到本地
这里怎么保存的不用我多说吧,重点在后面的分析过程


三、通过16进制分析工具进行数据分析
我这里使用的是
WinHex,其他的工具都大同小异,自行选择
3.1 ttpkg的文件结构
这里通过搜索引擎查找相关资料,居然只找到一篇相关的,大概结构可参考这篇文章:https://blog.csdn.net/weixin_29002961/article/details/117869108
这里贴出文件的大概结构信息(实际肯定有差距)
3.2 通过WinHex分析数据
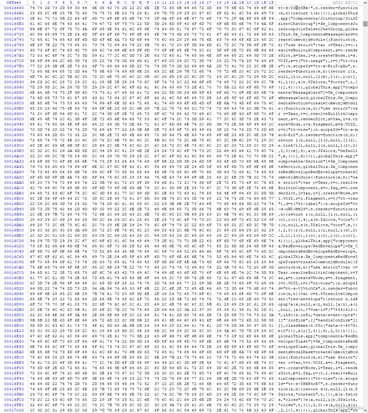
打开文件,第一眼就可以看到大量的明文数据,前四个字节是
固定标识,后面很多文件路径之类的东西,再往下翻会看到文件内容之类的东西文件头
部分文件内容
我这里复制了一份
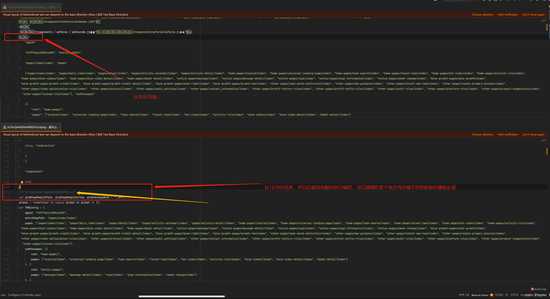
导入到可以格式化代码的编辑器里面,通过代码格式化可以看出大概的文件结构
之所以要复制一份是防止破坏源文件的结构(你猜我是怎么知道的[手动狗头])我这里使用的phpstorm导入的文件,通过代码格式化后可以看到
31行有一个json的开始,并且没有乱码之类的,结束的地方在1210行,后面再跟的就是一个js代码的开头了,可以猜测在文件的某个地方存有文件开始位置和结束位置或者文件长度的数据
打开WinHex在文件顶部,查看两个明文之间的间距是多少,这种一般都会有一定的规律,这里看到间距的长度为
C,C是16进制的,所以在十进制中代表的12,也就是每个明文路径之间有十二个字节的间距,这里经过多次对比后确定长度就是C


3.3 对比每组数据的差异与共同点
选中数据后点鼠标右键选择
编辑-复制选块-十六进制数值
>
然后粘贴到编辑器里面,并把每个端后面的文件名复制到后面,按照两个字符为一组用空格进行分割,下面是我分析出来的数据
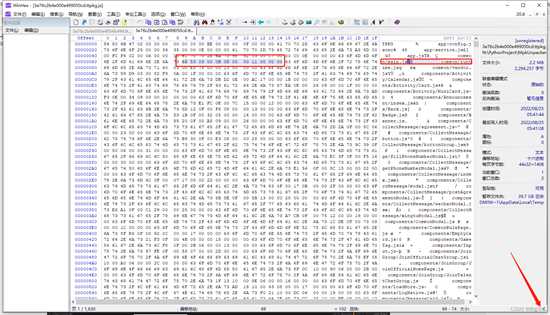
蓝色框里代表不同的数据,红色框里代表相同的数据,通过分析可得出第三个框里的数据为文件名称的长度,其余的都是结构体剩余的字节,比如
int类型占用四个字节,'app-service.js'的长度为14,所以对应的16进制为E,'app.js'的长度为6,在16进制里也就是'6',这里定位了文件名称长度的位置,就是每段空白字符的第9-12个字节,因为使用的是大端存储的,所以是逆序的,大端存储和小端存储可以百度一下。
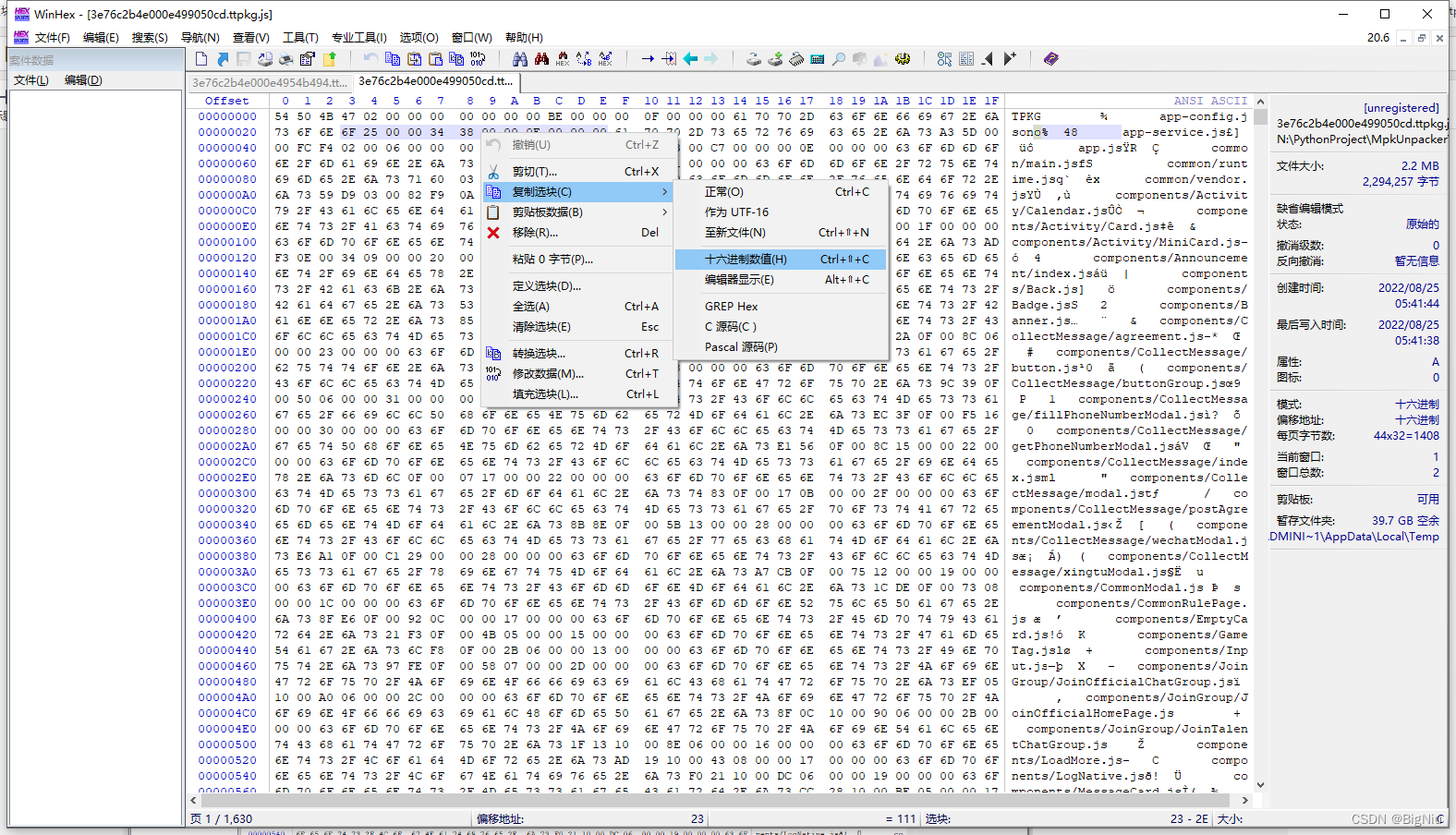

文件顶部数据比较特殊,通过之前的分析可分析出以下数据:版本号、4个空字节占用、文件个数、第一个文件名称长度,这里我们发现文件头里面并没有我们需要的文件起始位置和结束位置的信息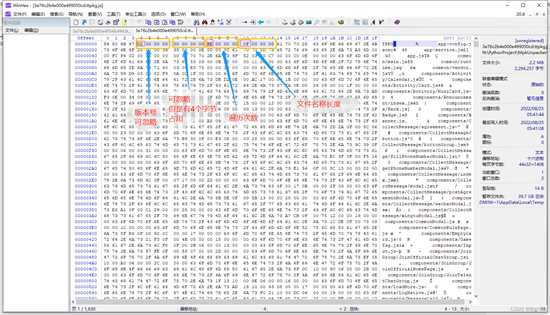
3.4 定位文件起始位置和结束位置
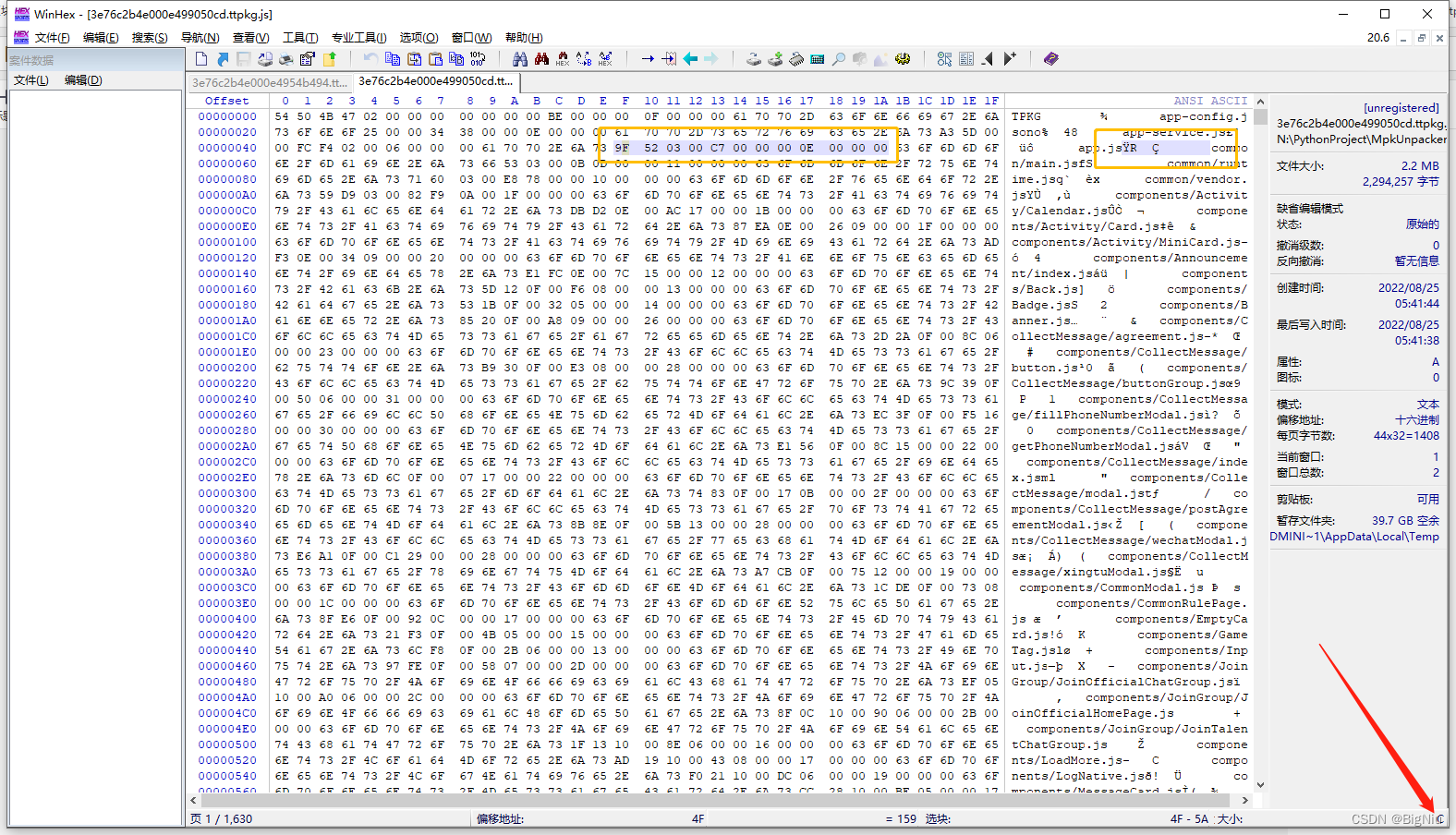
因为第一个文件为json,所以我们就会想起最开始的那个json头,先找一下偏移位置是多少,再去数据里找相应的16进制数据。这里就定位了文件名称后面第一个4个字节就是我们要找的文件内容开始位置,因为使用的大端存储,所以是逆序的,源数据为:
6F 25 00 00,通过逆序后就是00 00 25 6F,跟我们手动找到的文件头偏移地址一致
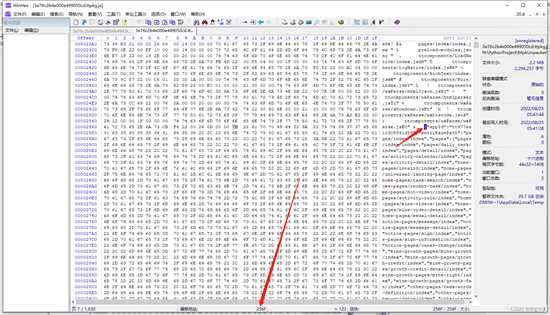
数据长度也通过同样的方式分析,通过右键把json开始的{设置为选块起始位置,再把结尾的地方选择为选块结束位置,即可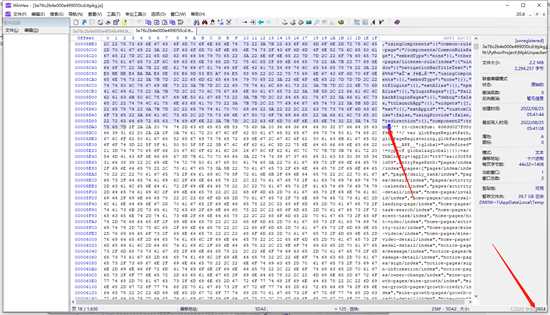
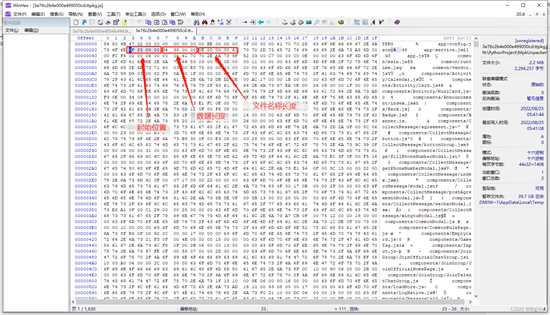
OK,至此所需要的数据就找完了,有了这些数据就可以把文件名称对应的文件内容写出来了
最终解包效果图如下: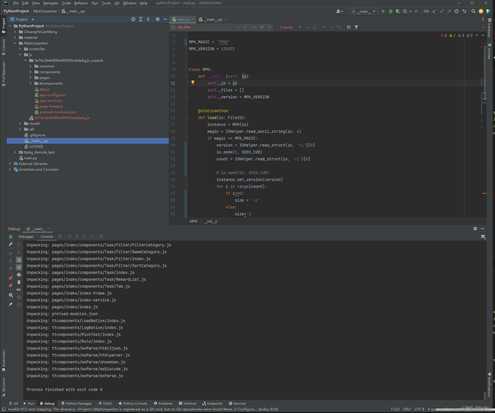
 ttpkgUnpacker.rar2022-9-5 20:16 上传点击文件名下载附件
ttpkgUnpacker.rar2022-9-5 20:16 上传点击文件名下载附件下载积分: 吾爱币 -1 CB
更新日志
- 【雨果唱片】中国管弦乐《鹿回头》WAV
- APM亚流新世代《一起冒险》[FLAC/分轨][106.77MB]
- 崔健《飞狗》律冻文化[WAV+CUE][1.1G]
- 罗志祥《舞状元 (Explicit)》[320K/MP3][66.77MB]
- 尤雅.1997-幽雅精粹2CD【南方】【WAV+CUE】
- 张惠妹.2007-STAR(引进版)【EMI百代】【WAV+CUE】
- 群星.2008-LOVE情歌集VOL.8【正东】【WAV+CUE】
- 罗志祥《舞状元 (Explicit)》[FLAC/分轨][360.76MB]
- Tank《我不伟大,至少我能改变我。》[320K/MP3][160.41MB]
- Tank《我不伟大,至少我能改变我。》[FLAC/分轨][236.89MB]
- CD圣经推荐-夏韶声《谙2》SACD-ISO
- 钟镇涛-《百分百钟镇涛》首批限量版SACD-ISO
- 群星《继续微笑致敬许冠杰》[低速原抓WAV+CUE]
- 潘秀琼.2003-国语难忘金曲珍藏集【皇星全音】【WAV+CUE】
- 林东松.1997-2039玫瑰事件【宝丽金】【WAV+CUE】