为学习spark,虚拟机中开4台虚拟机安装spark3.0.0
底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境
首先,去http://spark.apache.org/downloads.html下载对应安装包

解压
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local [hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark [hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四个节点都添加环境变量
export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目录中的conf目录下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11 export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/usr/local/hadoop export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work节点,cp ./conf/slaves.template ./conf/slaves修改为
master
slave1
slave2
slave3
写死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
复制spark目录到其他节点
sudo scp -r /usr/local/spark/ slave1:/usr/local/ sudo scp -r /usr/local/spark/ slave2:/usr/local/ sudo scp -r /usr/local/spark/ slave3:/usr/local/ sudo chown -R hadoop ./spark/
...
启动集群
先启动hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后启动spark集群

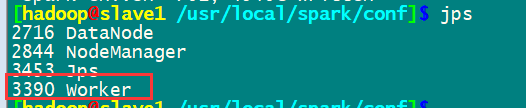
通过master8080端口监控

完成安装
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件!
如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
千金楼资源网 Copyright www.htabc.com
暂无“ol7.7安装部署4节点spark3.0.0分布式集群的详细教程”评论...
更新日志
2024年11月15日
2024年11月15日
- 谭咏麟《20世纪中华歌坛名人百集珍藏版》[WAV+CUE][1G]
- 炉石传说40轮盘术最新卡组代码在哪找 标准40轮盘术卡组代码分享
- 炉石传说亲王贼怎么玩 2024亲王贼最新卡组代码分享
- 炉石传说30.6.2补丁后有什么卡组 30.6.2最强卡组最新推荐
- 模拟之声慢刻CD《蔡琴名曲回顾遇听》[原抓WAV+CUE]
- BruceLiu-WAVES(MusicbySatie)(2024)2CD[24Bit-96kHz]FLAC
- KonstantinKrimmel-MythosSchubertLoewe(2024)[24Bit-96kHz]FLAC
- 2024雷蛇高校挑战赛 嘤式分解助力收官之战
- 海信发布110吋世俱杯官方定制AI电视 引领智能观赛
- 海信发布27英寸显示器大圣G5 Pro:采用自研超解析芯片、友达原厂模组
- 蔡琴《机遇》1:1母盘直刻日本头版[WAV分轨][1.1G]
- 陈百强《与你几分钟的约会》XRCD+SHMCD限量编号版[低速原抓WAV+CUE][994M]
- 陈洁丽《监听王NO.1 》示范级发烧天碟[WAV+分轨][1.1G]
- 单色凌.2014-小岁月太着急【海蝶】【WAV+CUE】
- 陈淑桦.1988-抱紧我HOLD.ME.NOW【EMI百代】【WAV+CUE】